
Aujourd’hui j’ai installé Python et Django sur mon système Windows pour essayer de faire un petit site web rapidement, disons avant la fin de la journée.
Je commence donc ma configuration sur mon système Windows et en parallèle je fais la même chose en SSH sur une console MSYS2,une VM en mode console d’un système linux pour faire simple.
Sur windows je teste alors que sur la console MYSYS je suis connecté à mon serveur dédié de l’autre côté de la France mon serveur de production en quelque sorte.
Arrivé à l’étape d’installation de Django sur mon Windows, j’ai un message qui attire mon attention. Il semblerait qu’il manque un chemin dans PATH.

Pas de soucis. Touche Windows, j’écris « path » et j’appuie sur entrée. Je me retrouve sur les propriétés système.
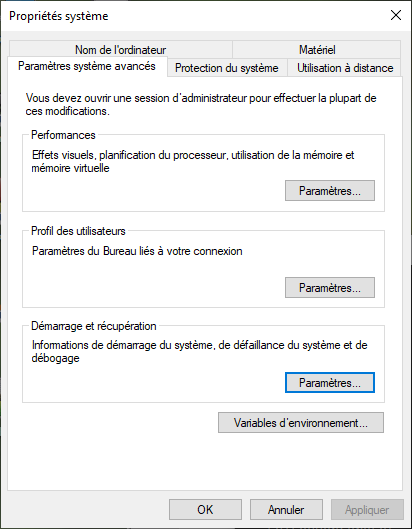
Un clic de plus sur « Variables d’environnement… » et je me retrouve devant deux choix.
- Variables utilisateur pour MonOrdinateur
- Variables système
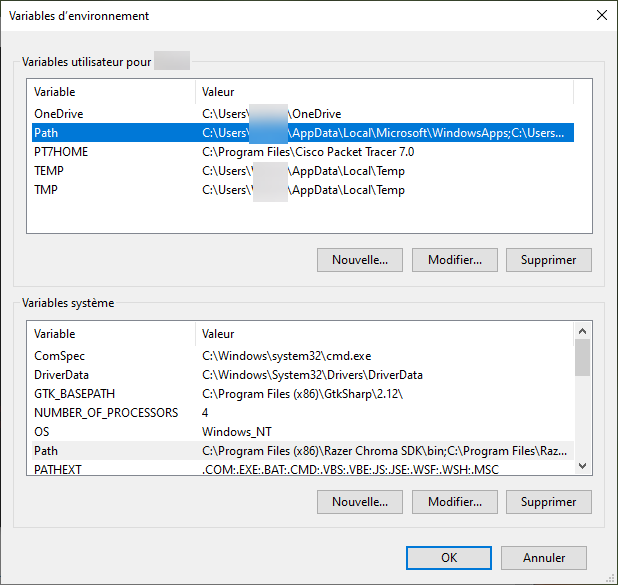
Dans les deux cas j’ai accès à une variable PATH que je peux modifier. Je ne me pose pas plus de questions et je modifie la variable Path dans variables système et y ajoute mon chemin.
Je valide tout, je suis content, tout va marcher et la commande
django-admin --version
devrait enfin m’afficher quelque chose à l’écran. Mais ce n’est pas le cas…
Je retourne dans les propriétés système et je commence vraiment à avoir peur. Plus aucuns chemins n’est accessible dans la liste PATH des variables système. Je pose la question à mon moteur de recherche qui m’indique qu’une restauration est le seul moyen de retrouver mes données perdues. Mais pour cela, il faut un point de restauration.
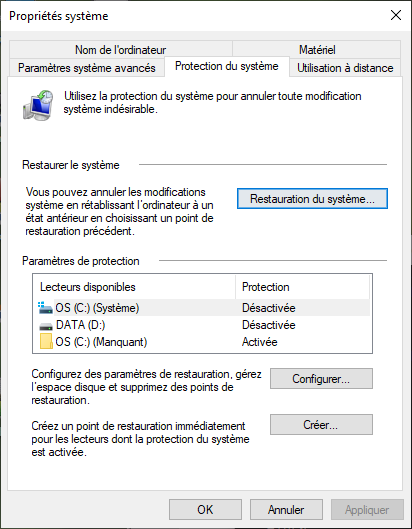
Je n’ai pas de point de restauration actif, la protection du système semble désactivée.
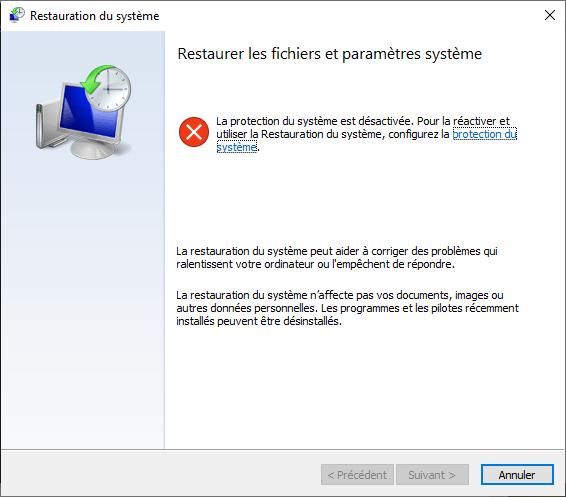
Je continue les recherches avec de moins en moins d’espoir de pouvoir redémarrer mon système dans de bonne condition. Pour ce qui ne le savent pas, les variables système dans PATH conditionnent beaucoup de chemins vers des exécutables utiles au bon fonctionnement de votre ordinateur.
Plus d’une heure passe, en désespoir de cause je récupère quelques PATH sur un autre ordinateur et un ami m’envoie les siens, mais je vois bien qu’il n’y a pas tous les chemins que j’avais avant de tout casser.
Quand mes recherches prennent un tournant inattendu. Je trouve enfin quelque chose d’intéressant. On peut exécuter la commande set pour lister et modifier les variables d’environnement et système propre à l’exécution d’un interpréteur de commande (CMD). D’ailleurs si on modifie des chemins dans l’interpréteur et qu’on le quitte, les chemins ajoutés ne sont pas sauvegardés. De la même manière si j’ai modifié les variables PATH par l’interface graphique sans relancer l’interpréteur celui-ci connait encore les anciennes valeurs de PATH.
J’ai un sursaut d’excitation. Est-ce que j’ai encore une CMD ouverte ?
Malheureursment non. Je n’ai plus aucune CMD ouvertes dans la barre des tâches. Par contre il y a toujours MYSYS ouvert avec une connexion SSH en cours vers mon serveur.
Se pourrait-il que j’avais la solution pour récupérer mes variables système PATH sous les yeux depuis le début ?
Après avoir mis fin à la connexion ssh avec le serveur. Le verdict. Je tape au hasard la commande Windows « SET » dans l’interpréteur MYSYS Linux. Un résultat ! Peut être que j’ai de la chance après tout ? Je fracasse la molette pour remonter rapidement tout en haut de la sortie affichée, quand enfin j’ai ce que je cherchais !
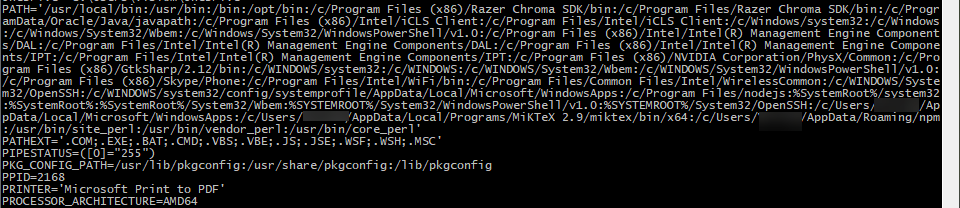
Toutes mes variables PATH gardées en mémoire par MSYS2. Avec pour seul inconvénient un typage Unix et non Windows. Dix minutes plus tard j’ai mes variables système PATH d’origine. Et en bonus, j’ai même compris mon erreur. J’aurais du mettre mon chemin dans les variables utilisateur et vérifier qu’il était bien écrit. En plus j’aurais pu tester que tout fonctionne en le faisant avec la commande set en console avant de faire la modification réel.
Conclusion
Si vous perdez toutes vos variables système ou variables utilisateur sur Windows vous pouvez les récupérer en dernier recours si il vous reste une console ouverte avant la réalisation des modifications qui ont détruits vos chemins. Pour les trouver il suffit de taper la commande « set » ou « path » dans cette console et de récupérer et mettre en forme les chemins, puis de les réinsérer par l’interface graphique dans PATH en vérifiant si ce sont des variables utilisateur ou système.
Pour la petite astuce, ne faites pas comme moi et pensez à faire des points de restauration système réguliers.
