
Avant-propos
Cet article va présenter une technologie complémentaire (BIRT) utilisée dans le cadre d’un projet de gestion de cours en ligne fait en TP de Java à l’UTBM.
BIRT (The Business Intelligence and Reporting Tool) est un projet de la communauté Eclipse comprenant un générateur de rapports, un générateur de graphique ainsi qu’un environnement de conception. Heureusement pour nous il n’est pas nécessaire de développer sur Eclipse pour l’utiliser. Mais il vous faudra tout de même installer le BIRT report designer que vous pouvez trouver sur cette page.
Prérequis
Le BIRT report designer est nécessaire pour la génération d’un fichier .rptdesign qui vous sera demandé par la suite.
Ajout de la bonne dépendance (org.eclipse.birt.runtime) dans le fichier pom.xml de votre projet que vous pouvez trouver ici par exemple.
Tutoriel : Générer un fichier PDF sur clic dans une servlet avec BIRT
Les deux classes suivantes sont à ajouter dans votre projet.
Ainsi vous avez la première classe appelée par la servlet et permettant de démarrer le Report Engine.
public class BirtEngine {
private static IReportEngine birtEngine = null;
private static Properties configProps = new Properties();
private final static String configFile = "BirtConfig.properties";
public static synchronized void initBirtConfig() {
loadEngineProps();
}
public static synchronized IReportEngine getBirtEngine(ServletContext sc) {
if (birtEngine == null)
{
EngineConfig config = new EngineConfig();
if( configProps != null){
String logLevel = configProps.getProperty("logLevel");
Level level = Level.OFF;
if ("SEVERE".equalsIgnoreCase(logLevel))
{
level = Level.SEVERE;
} else if ("WARNING".equalsIgnoreCase(logLevel))
{
level = Level.WARNING;
} else if ("INFO".equalsIgnoreCase(logLevel))
{
level = Level.INFO;
} else if ("CONFIG".equalsIgnoreCase(logLevel))
{
level = Level.CONFIG;
} else if ("FINE".equalsIgnoreCase(logLevel))
{
level = Level.FINE;
} else if ("FINER".equalsIgnoreCase(logLevel))
{
level = Level.FINER;
} else if ("FINEST".equalsIgnoreCase(logLevel))
{
level = Level.FINEST;
} else if ("OFF".equalsIgnoreCase(logLevel))
{
level = Level.OFF;
}
config.setLogConfig(configProps.getProperty("logDirectory"), level);
}
IPlatformContext context = new PlatformServletContext( sc );
config.setPlatformContext( context );
try
{
Platform.startup( config );
}
catch ( BirtException e )
{
e.printStackTrace( );
}
IReportEngineFactory factory = (IReportEngineFactory) Platform
.createFactoryObject( IReportEngineFactory.EXTENSION_REPORT_ENGINE_FACTORY );
birtEngine = factory.createReportEngine( config );
}
return birtEngine;
}
public static synchronized void destroyBirtEngine() {
if (birtEngine == null) {
return;
}
birtEngine.shutdown();
Platform.shutdown();
birtEngine = null;
}
public Object clone() throws CloneNotSupportedException {
throw new CloneNotSupportedException();
}
private static void loadEngineProps() {
try {
//Config File must be in classpath
ClassLoader cl = Thread.currentThread ().getContextClassLoader();
InputStream in = null;
in = cl.getResourceAsStream (configFile);
configProps.load(in);
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
La classe de la servlet que vous appellerez pour générer votre fichier pdf.
public class WebReportServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
private IReportEngine birtReportEngine = null;
protected static Logger logger = Logger.getLogger( "org.eclipse.birt" );
public WebReportServlet() {
super();
}
@Override
public void destroy() {
super.destroy();
BirtEngine.destroyBirtEngine();
}
@Override
public void doGet(HttpServletRequest req, HttpServletResponse resp)
throws ServletException, IOException {
resp.setContentType( "application/pdf" );
resp.setHeader ("Content-Disposition","inline; filename=test.pdf");
String reportName = "test.rptdesign";
String param1 = req.getParameter("param_1");
ServletContext sc = req.getSession().getServletContext();
this.birtReportEngine = BirtEngine.getBirtEngine(sc);
IReportRunnable design = null;
try
{
//Open report design
design = birtReportEngine.openReportDesign( sc.getRealPath("/Reports")+"/"+reportName );
//create task to run and render report
IRunAndRenderTask task = birtReportEngine.createRunAndRenderTask( design );
int parameter1 = 0;
try{
parameter1 = new Integer(param1);
} catch (Exception e){
parameter1 = 0;
}
if(parameter1 >= 1){
task.setParameterValue("param_1", parameter1);
}
else{
task.setParameterValue("param_1", 0);
}
//set output options
HTMLRenderOption options = new HTMLRenderOption();
options.setOutputFormat(HTMLRenderOption.OUTPUT_FORMAT_PDF);
options.setOutputStream(resp.getOutputStream());
task.setRenderOption(options);
//run report
task.run();
task.close();
} catch (Exception e){
e.printStackTrace();
throw new ServletException( e );
}
}
@Override
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
}
}
Assurez vous d’avoir mappé votre servlet correctement ici le mappage est réalisé dans le fichier web.xml comme ceci :
<servlet>
<servlet-name>birtServlet</servlet-name>
<servlet-class>
com.coursenligne.servlet.WebReportServlet
</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>birtServlet</servlet-name>
<url-pattern>/birt</url-pattern>
</servlet-mapping>
Dans le cas présent l’appel à l’adresse suivante via votre navigateur…
http://localhost/webapp/birt?param_1=1
… ne vous donnera pas le résultat escompté, en cause la ligne suivante :
design = birtReportEngine.openReportDesign( sc.getRealPath("/Reports")+"/"+reportName );
Le design en question est un fichier. Celui dont je vous parlais plus tôt au format .rptdesign. Il est à placer dans le répertoire cible (Attention : le placement de votre dossier de placement déterminera aussi la visibilité des documents contenus, voir visibilité de WEB-INF).
 Heureusement pour vous, après vérification on peut voir que le mot de passe de votre base de données est chiffré. Moins d’inquiétude donc si l’on tombait par hasard sur votre fichier de design.
Heureusement pour vous, après vérification on peut voir que le mot de passe de votre base de données est chiffré. Moins d’inquiétude donc si l’on tombait par hasard sur votre fichier de design.
<encrypted-property name="odaPassword" encryptionID="base64">Y291cnM=</encrypted-property>
Comme vous l’avez peut-être constaté vous ne pouvez exécuter le code précédent, et pour cause il vous faut générer le fichier de design. Prochaine étape donc, le BIRT report designer qui se présente comme ci-dessous.
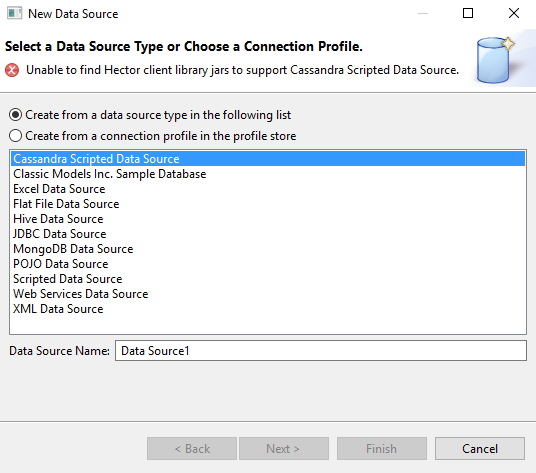
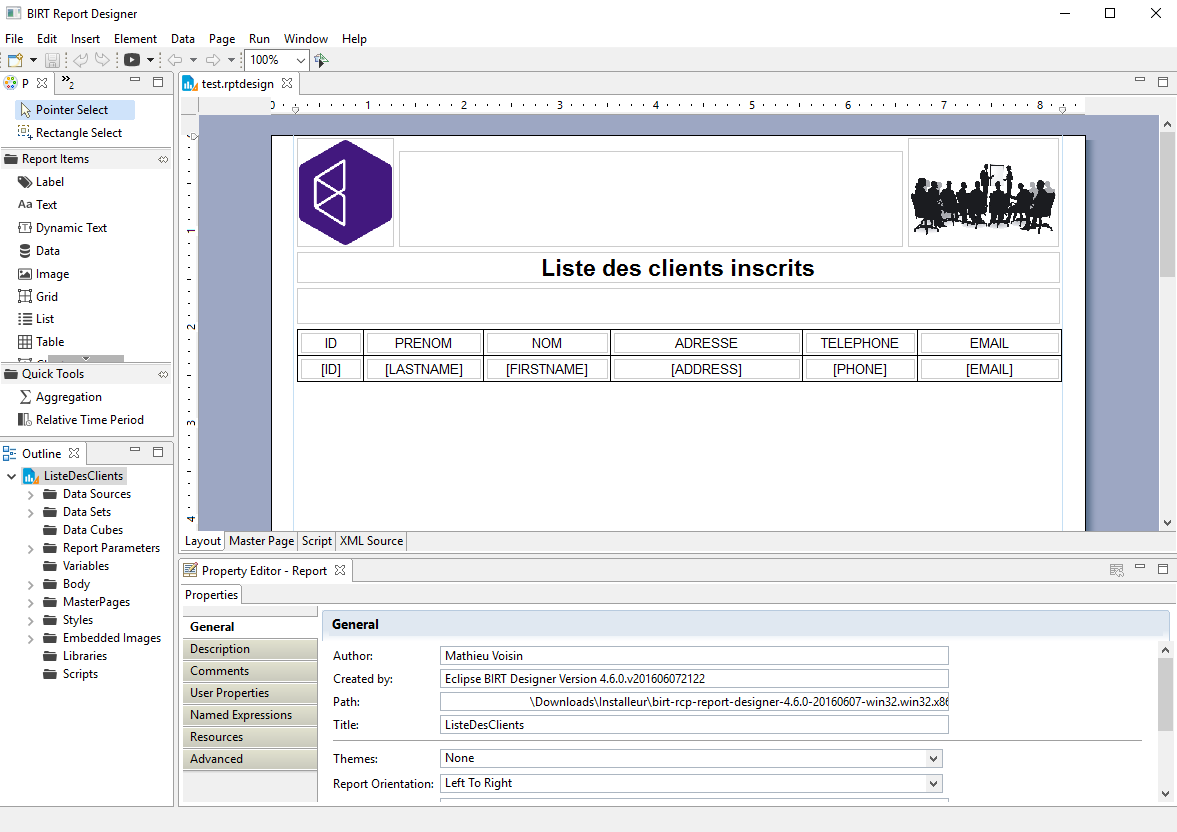 Rien de bien nouveau pour ceux qui utilisent régulièrement toutes sortent d’IDE. Pour accéder à vos données (Data Source) vous aurez plusieurs choix, cliquez sur l’onglet « Data Explorer » dans la colonne de gauche. Puis clic droit sur « Data Sources » et « New Data Source » plusieurs choix s’offrent à vous.
Rien de bien nouveau pour ceux qui utilisent régulièrement toutes sortent d’IDE. Pour accéder à vos données (Data Source) vous aurez plusieurs choix, cliquez sur l’onglet « Data Explorer » dans la colonne de gauche. Puis clic droit sur « Data Sources » et « New Data Source » plusieurs choix s’offrent à vous.
 Ici pour une question de simplicité j’ai choisi d’utiliser « JDBC Data Source », ajoutez y les paramètres de connexion à votre base de données. Ensuite créez un Data Set qui va vous permettre de récupérer le précieux sésame (vos données).
Ici pour une question de simplicité j’ai choisi d’utiliser « JDBC Data Source », ajoutez y les paramètres de connexion à votre base de données. Ensuite créez un Data Set qui va vous permettre de récupérer le précieux sésame (vos données).
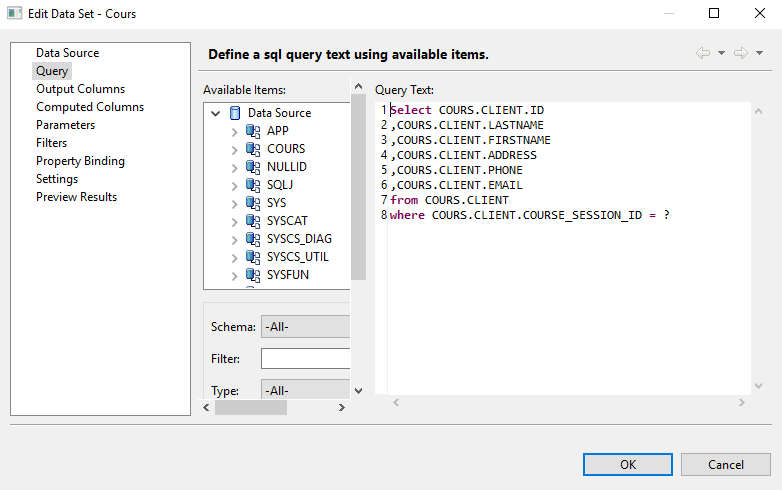 La clause where présente va ajouter un param dans « Parameters »
La clause where présente va ajouter un param dans « Parameters »
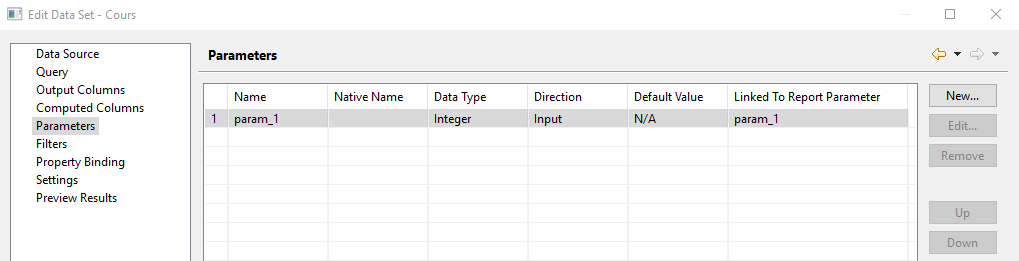
Si vous voulez que la génération de votre fichier pdf prenne en compte un paramètre passé dans la barre de recherche éditez simplement la ligne en activant « Linked To Report Parameter » comme ceci :
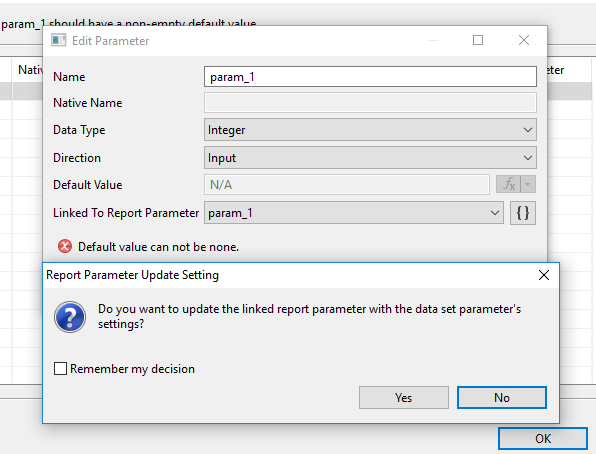 Voilà vous êtes fin prêt à générer votre fichier pdf, il suffit d’ajouter un bouton pointant sur la bonne URL avec les bons paramètres !
Voilà vous êtes fin prêt à générer votre fichier pdf, il suffit d’ajouter un bouton pointant sur la bonne URL avec les bons paramètres !
En conclusion
Les deux grandes difficultés que j’ai pu rencontrer lors de la mise en place de la génération automatique de PDF à l’aide de BIRT a été la vieillesse des résultats retournés par les moteurs de recherches. L’âge du projet BIRT en est la cause (de 2005 à maintenant). La deuxième difficulté a été de comprendre que le .rptdesign est obligatoire pour générer un pdf même si nous voulons le générer de manière programmatique. Un dernier point noir est la difficulté de trouver une documentation BIRT digne de ce nom.
L’opinion neutre est que l’utilisation du BIRT report designer par un informaticien n’est pas la chose la plus ancrée dans ses gênes bien que vous ayez des tonnes de paramètres très proches du HTML/CSS on est dans notre droit de demander si ils n’auraient pas pu intégrer directement les mêmes balises dans les .rptdesign au lieu de faire à leur sauce et nous obliger à utiliser le designer.
Les points positifs sont la facilité à postériori (une fois la technologie domptée) de générer un fichier pdf par simple clic dans notre application avec les données directement trouvées dans notre base de données.
J’avais utiliser FPDF en PHP pour la génération de facture automatique en stage de fin d’IUT et j’avais trouvé l’utilisation / intégration dans ne application existante très facile. Dans le cas de FPDF toute la génération est programmée en PHP un vrai plus si vous êtes développer et que la tâche à réaliser est bien définie et ne changera pas tous les 10 du mois. A l’inverse, mon utilisation de BIRT me laisse porter à croire que son utilisation au sein d’une moyenne ou grande entreprise est fort appréciable, avec quand même dans l’obligation de maitriser correctement le BIRT report designer et ses nuances ! Un petit avantage aussi pour la modification d’un design déjà existant, vous voulez ajouter une image ? Importer la dans le designer et glisser la à l’endroit souhaité (Quid par contre de la mise en page qu’il faudra revoir mais au moins ici vous avez un retour visuel direct).
Code source inspiré de : Wiki officiel BIRT servlet
